2.1. Cool Tools#
2.1.1. Work with Countries, Currencies, Subdivisions, and more#
Do you work with international data?
You probably know how important it is to use the correct codes for countries, currencies, languages, and subdivisions.
To save the headache, try pycountry for Python!
pycountry makes it easy to work with these codes.
It allows you to look up country and currency information by name or code based on ISO.
But it can also be used to get the name or code for a specific currency or country.
!pip install pycountry
import pycountry
# Get Country
print(pycountry.countries.get(alpha_2="DE"))
# Get Currency
print(pycountry.currencies.get(alpha_3="EUR"))
# Get Language
print(pycountry.languages.get(alpha_2='DE'))
2.1.2. Generate better requirements files with pipreqs#
To generate a requirements.txt file, don’t do pip freeze > requirements.txt
It will save all packages in your environment including those you are not currently using in your project (but still have installed).
Instead, use pipreqs.
pipreqs will only save those packages based on imports in your project.
A very good option for plain virtual environments.
!pip install pipreqs
!pipreqs .
2.1.3. Remove a package and its dependencies with pip-autoremove#
When you want to remove a package via pip, you will encounter following problem:
pip will remove the desired package but not its unused dependencies.
Instead, try pip-autoremove.
It will automatically remove a package and its unused dependencies.
A really good option when you are not using something like Poetry.
!pip install pip-autoremove
!pip-autoremove flask -y
2.1.4. Get distance between postal codes#
Do you want the distance between two postal codes?
Use pgeocode.
Just specify your country + postal codes and get the distance in KM.
!pip install pgeocode
import pgeocode
dist = pgeocode.GeoDistance('DE')
dist.query_postal_code('10117', '80331')
2.1.5. Working with units with pint#
Have you ever struggled with units in Python?
With pint, you don’t have to.
pint is a Python library for easy unit conversion and manipulation.
You can handle physical quantities with units, perform conversions, and perform arithmetic with physical quantities.
With pint, you keep track of your units and ensure accurate results.
!pip install pint
import pint
# Initializing the unit registry
ureg = pint.UnitRegistry()
# Defining a physical quantity with units
distance = 33.0 * ureg.kilometers
print(distance)
# 33.0 kilometer
# Converting between units
print(distance.to(ureg.feet))
# 108267.71653543308 foot
# Performing arithmetic operations
speed = 6 * distance / ureg.hour
print(speed)
# 198.0 kilometer / hour
2.1.6. Supercharge your Python profiling with Scalene#
Want to identify Python performance issues?
Try Scalene, your Profiler on steroids!
Scalene is a Python CPU + GPU + Memory profiler to identify bottlenecks.
Even with AI-powered optimization proposals!
Scalene comes with an easy-to-use CLI and web-based GUI.
!pip install scalene
!scalene <my_module.py>
2.1.7. Fix unicode errors with ftfy#
Have you ever struggled with Unicode errors in your Python code?
Try ftfy!
ftfy repairs scrambled text which occurs as a result of encoding or decoding problems.
You will probably know it when text in a foreign language can’t appear correctly.
In Python you only have to call one method from ftfy to fix it.
!pip install ftfy
import ftfy
print(ftfy.fix_text('What does “ftfyâ€\x9d mean?'))
print(ftfy.fix_text('✔ Check'))
print(ftfy.fix_text('The Mona Lisa doesn’t have eyebrows.'))
2.1.8. Remove the background from images with rembg#
Do you want to remove the background from images with Python?
Use rembg.
With its pre-trained models, rembg makes removing the background of your images easy.
!pip install rembg
from rembg import remove
import cv2
input_path = 'car.jpg'
output_path = 'car2.jpg'
input_file = cv2.imread(input_path)
output_file = remove(input_file)
cv2.imwrite(output_path, output_file)
2.1.9. Build modern CLI apps with typer#
Tired of building clunky CLI for your Python applications?
Try typer.
typer makes it easy to create clean, intuitive CLI apps that are easy to use and maintain.
It also comes with auto-generated help messages.
Ditch argparse.
!pip install typer
# hello_script.py
import typer
app = typer.Typer()
@app.command()
def hello(name: str):
typer.echo(f"Hello, {name}!")
@app.command()
def bye(name: str):
typer.echo(f"Bye, {name}!")
if __name__ == "__main__":
app()
!python hello_script.py hello John
2.1.10. Generate realistic fake data with faker#
Creating realistic test data for your Python projects is annoying.
faker helps you to do that!
With just a few lines of code, you can generate realistic and diverse test data, such as :
Names
Addresses
Phone numbers
Email addresses
Jobs
And more!
You can even set the local or language for more diverse output.
!pip install faker
from faker import Faker
fake = Faker('fr_FR')
print(fake.name())
print(fake.job())
print(fake.phone_number())
2.1.11. Enrich your progress bars with rich#
Do you want a more colorful output for progress bars?
Use rich
rich offers a beautiful progress bar, instead of tqdm’s boring output.
With rich.progress.track, you can get a colorful output.
!pip install rich
from rich.progress import track
for url in track(range(25000000)):
# Do something
pass
2.1.12. Set the description for tqdm bars#
When you work with progress bars, you will probably use 𝐭𝐪𝐝𝐦.
Do you know you can add descriptions to your bar?
You can do that with set_description().
import tqdm
import glob
files = tqdm.tqdm(glob.glob("sample_data/*.csv"))
for file in files:
files.set_description(f"Read {file}")
2.1.13. Convert Emojis to Text with emot#
Analyzing emojis and emoticons in texts can give you useful insights.
With emot, you can convert emoticons into words.
Especially useful for sentiment analysis.
!pip install emot
import emot
emot_obj = emot.core.emot()
text = "I love python ☮ 🙂 ❤ :-) :-( :-)))"
emot_obj.emoji(text)
2.1.14. Print hardware information and version numbers#
When raising an issue, you should provide version numbers and hardware information.
With watermark, you can do that easily.
Just install the package and print.
!pip install watermark
from watermark import watermark
print(watermark())
2.1.15. Cache requests with requests-cache#
Do you want better performance for requests?
Use requests-cache.
It caches HTTP requests so you don’t have to make the same requests again and again.
In the example below, a test endpoint with a 1-second delay will be called.
With the standard requests library, this takes 60 seconds.
With requests-cache, this takes 1 second.
!pip install requests-cache
# This takes 60 seconds
import requests
session = requests.Session()
for i in range(60):
session.get('https://httpbin.org/delay/1')
# This takes 1 second
import requests_cache
session = requests_cache.CachedSession('test_cache')
for i in range(60):
session.get('https://httpbin.org/delay/1')
2.1.16. Unify messy columns with unifyname#
Do you want to unify messy string columns?
Try unifyname, based on fuzzy string matching.
This small library cleans up your messy columns with 100s of different variations for one word.
!pip install unifyname
import pandas as pd
from unifyname.utils import unify_names, deduplicate_list_string
data = pd.read_csv("")
data["BAIRRO DO IMOVEL"].value_counts()
data = unify_names(data,column='BAIRRO DO IMOVEL',threshold_count=500)
data["BAIRRO DO IMOVEL"].value_counts()
2.1.17. Check for broken links in a website#
𝐥𝐢𝐧𝐤𝐜𝐡𝐞𝐜𝐤𝐞𝐫 is a Python library for recursively going through a website and checking for broken links.
You may not have the time to do that manually.
And broken links can harm your Search Engine Ranking.
See below how easy it can be to set up and use.
!pip install linkchecker
!linkchecker https://www.example.com
2.1.18. Matplotlib for your Terminal#
bashplotlib is a little library that displays basic ASCII graphs in your terminal.
It provides a quick way to visualize your data.
Currently, bashplotlib only supports histogram and scatter plots.
!pip install bashplotlib
!hist --file test.txt
2.1.19. Display a Dependency Tree of your Environment#
Do you want to stop resolving dependency issues?
Try pipdeptree.
pipdeptree displays your installed Python packages in the form of a dependency tree.
It will also show you warnings when there are possible version conflicts.
An alternative to tools like Poetry which resolves dependency issues for you automatically.
!pip install pipdeptree
!pipdeptree
2.1.20. Sort LaTeX acronyms automatically#
I wrote a small library (acrosort-tex) to sort LaTeX acronyms with one command automatically.
It was a fun Sunday project where I really learned how easy it is to publish a package with Poetry.
Currently, it only supports acronyms in the following format:
\𝒂𝒄𝒓𝒐{𝒂𝒃𝒃𝒓𝒆𝒗𝒊𝒂𝒕𝒊𝒐𝒏}[𝒔𝒉𝒐𝒓𝒕𝒇𝒐𝒓𝒎]{𝒍𝒐𝒏𝒈𝒇𝒐𝒓𝒎}
but it’s a beginning :)
See below for a small example.
Link to the repository: https://lnkd.in/eTF8qs5w
!pip install acrosort_tex
!acrosort old.tex new.tex
2.1.21. Make ASCII Art from Text#
Create ASCII Art From Text in your Terminal
With pyfiglet, you can generate banner-like text with Python.
This is a nice feature to introduce your users to your Python CLI apps.
!pip install pyfiglet
# Default font
ascii_art = pyfiglet.figlet_format('Hello, world!')
# Alphabet font
ascii_art = pyfiglet.figlet_format('Hello, world!', font='Alphabet')
# Bubblehead font
ascii_art = pyfiglet.figlet_format('Hello, world!', font='bulbhead')
2.1.22. Display NER with spacy#
If you want to perform and visualize Named-entity Recognition, use spacy.displacy.
It makes NER and visualizing detected entities super easy.
displacy has some other cool tools like visualizing dependencies within a sentence or visualizing spans, so check it out.
import spacy
from spacy import displacy
text = "Chelsea Football Club is an English professional football club based in Fulham, West London.\
Founded in 1905, they play their home games at Stamford Bridge. \
The club competes in the Premier League, the top division of English football. \
They won their first major honour, the League championship, in 1955."
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
displacy.render(doc, style="ent", jupyter=True)
2.1.23. Create TikZ pictures with Python#
If you have ever written a paper in LaTeX, you probably used TikZ for your graphics.
TikZ is probably the most powerful tool to create graphic elements.
And notoriously hard to learn.
No need to worry, you can create TikZ-figures in Python too.
With tikzplotlib, you can convert matplotlib figures into TikZ.
You can then insert the resulting plot in your LaTeX file.
Really useful when you don’t want the hassle with TikZ.
!pip install tikzplotlib
import tikzplotlib
import matplotlib.pyplot as plt
import numpy as np
plt.style.use("ggplot")
t = np.arange(0.0, 2.0, 0.1)
s = np.sin(2 * np.pi * t)
s2 = np.cos(2 * np.pi * t)
plt.plot(t, s, "o-", lw=4.1)
plt.plot(t, s2, "o-", lw=4.1)
plt.xlabel("time (s)")
plt.ylabel("Voltage (mV)")
plt.title("Simple plot $\\frac{\\alpha}{2}$")
plt.grid(True)
tikzplotlib.save("mytikz.tex")
2.1.24. Human-readable RegEx with PRegEx#
RegEx is notoriously nasty to read and write.
For a human-readable alternative, try PRegEx.
PRegEx is a Python library aiming to have an easy-to-remember syntax to write RegEx patterns.
It offers a way to easily break down a complex pattern into multiple simpler ones that can then be combined.
See below how we can write a pattern that matches any URL that ends with either “.com” or “.org” as well as any IP address for which a 4-digit port number is specified.
from pregex.core.classes import AnyLetter, AnyDigit, AnyFrom
from pregex.core.quantifiers import Optional, AtLeastAtMost
from pregex.core.operators import Either
from pregex.core.groups import Capture
from pregex.core.pre import Pregex
http_protocol = Optional('http' + Optional('s') + '://')
www = Optional('www.')
alphanum = AnyLetter() | AnyDigit()
domain_name = \
alphanum + \
AtLeastAtMost(alphanum | AnyFrom('-', '.'), n=1, m=61) + \
alphanum
tld = '.' + Either('com', 'org')
ip_octet = AnyDigit().at_least_at_most(n=1, m=3)
port_number = (AnyDigit() - '0') + 3 * AnyDigit()
# Combine sub-patterns together.
pre: Pregex = \
http_protocol + \
Either(
www + Capture(domain_name) + tld,
3 * (ip_octet + '.') + ip_octet + ':' + port_number
)
2.1.25. Perform OCR with easyOCR#
Effortlessly extract text from Images with EasyOCR
EasyOCR is a Python library for Optical Character Recognition (OCR), built on top of PyTorch.
It supports over 80 languages and writing scripts like Latin, Chinese, Arabic and Cyrillic.
See below how easy we can extract text from a given image.
PS: Even if it’s working on CPU, running on GPU is recommended.
!pip install easyocr
import easyocr
reader = easyocr.Reader(['en'])
image_path = 'english_image.png'
results = reader.readtext(image_path)
for result in results:
text = result[1]
print(text)
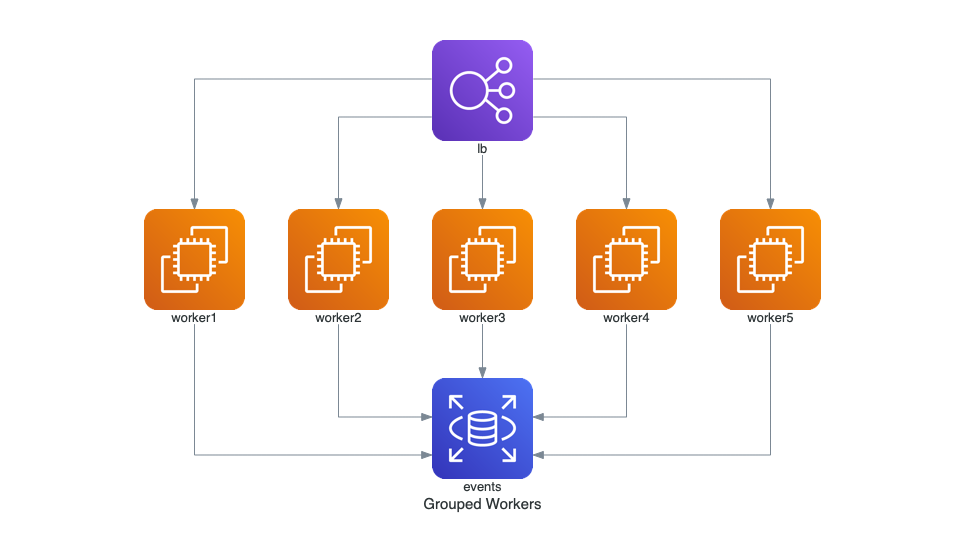
2.1.26. Diagram-as-Code with diagrams#
With the package diagrams, you can draw various types of diagrams with Python code.
It offers a simple syntax and nodes from many Cloud Providers like AWS, Azure or GCP.
See below how easy it is to draw a simple architecture.
!pip install diagrams
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
with Diagram("Grouped Workers", show=False, direction="TB"):
ELB("lb") >> [EC2("worker1"),
EC2("worker2"),
EC2("worker3"),
EC2("worker4"),
EC2("worker5")] >> RDS("events")
2.1.27. Powerful Retry Functionality with tenacity#
What, if an API call in your program fails?
Because of, let’s say, instable internet connection?
This is not so uncommon.
You usually should have some sort of retry mechanism in your program.
With tenacity in Python, this isn’t a problem anymore.
tenacity offers a retrying behaviour with a decorator with powerful features like:
Define Stop Conditions
Define Wait Conditions
Customize retrying on Exception
Retry on Coroutines
!pip install tenacity
import tenacity as t
# Stop after N attempts
@retry(stop=t.stop_after_attempt(5))
def stop_after_5_attempts():
print("Stopping after 5 attempts")
raise Exception
# OR Condition
@retry(stop=(t.stop_after_delay(10) | t.stop_after_attempt(5)))
def stop_after_10_s_or_5_retries():
print("Stopping after 10 seconds or 5 retries")
raise Exception
# Wait for X Seconds
@retry(wait=t.wait_fixed(2))
def wait_2_s():
print("Wait 2 second between retries")
raise Exception
# Retry for specific Exceptions
@retry(retry=t.retry_if_exception_type(IOError))
def might_io_error():
print("Retry forever with no wait if an IOError occurs, raise any other errors")
raise Exception
2.1.28. Performant Graph Analysis with python-igraph#
When you want to work with graphs in Python
Use python-igraph.
python-igraph offers a Python Interface to igraph, a fast and open source C library to manipulate and analyze graphs.
Due to its high performance, it can handle larger graphs for complex network research which you can visualize with matplotlib or plotly.
It’s documentation also offers neat tutorials for different purposes.
!pip install igraph
import igraph as ig
import matplotlib.pyplot as plt
g = ig.Graph(
6,
[(0, 1), (0, 2), (1, 3), (2, 3), (2, 4), (3, 5), (4, 5)]
)
g.es['width'] = 0.5
fig, ax = plt.subplots()
ig.plot(
g,
target=ax,
layout='circle',
vertex_color='steelblue',
vertex_label=range(g.vcount()),
edge_width=g.es['width'],
edge_color='#666',
edge_background='white'
)
plt.show()
2.1.29. Speedtests via CLI with speedtest-cli#
If you want to test your internet bandwidth via your CLI
try speedtest-cli.
speedtest-cli tests your internet bandwidth via speedtest(dot)net.
It’s installable via pip.
!pip install speedtest-cli
!speedtest-cli
2.1.30. Minimalistic Database for Python with tinydb#
Do you search for a minimalistic document-oriented database in Python?
Use tinydb.
tinydb is written in pure Python and offers a lightweight document-oriented database.
It’s perfect for small apps and hobby projects.
!pip install tinydb
from tinydb import TinyDB, Query
db = TinyDB('/path/to/db.json')
db.insert({'int': 1, 'char': 'a'})
db.insert({'int': 1, 'char': 'b'})
2.1.31. Calculate Code Metrics with radon#
How do you ensure your codebase stays clean and maintainable?
What if you can calculate how complex your codebase is?
There are different metrics to do that:
Raw Metrics like Source Lines of Code (SLOC) or Logical Lines of Code (LLOC). They are not a good estimator for the complexity.
Cyclomatic Complexity: Corresponds to the number of decisions in the code + 1 (e.g. every for or if counts).
Halstead Metrics: Metrics derived from the number of distinct and total operators and operands.
Maintainability Index: Measures how maintainable the code is. It’s a mix of SLOC, Cyclomatic Complexity, and a Halstead Metric.
With radon, you can calculate those metrics described above in Python (or via CLI).
!pip install radon
!radon cc example.py
2.1.32. Better Alternative to requests#
Want a better alternative to requests?
Use httpx for Python.
httpx is a modern alternative to requests to make HTTP requests (while having a similar API).
One of the main advantages is it supports asynchronous requests (while requests doesn’t).
This can lead to performance improvements when dealing with multiple endpoints concurrently.
Just try it for yourself.
!pip install httpx
import httpx
r = httpx.get('https://httpbin.org/get')
r = httpx.put('https://httpbin.org/put', data={'key': 'value'})
r = httpx.delete('https://httpbin.org/delete')
# Async support
async with httpx.AsyncClient() as client:
r = await client.get('https://www.example.com/')
2.1.33. Managing Configurations with python-dotenv#
Struggling with managing your Python project’s configuration?
Try python-dotenv.
python-dotenv reads key-value pairs from a .env file and can set them as environment variables.
You don’t have to hard-code those in your code.
!pip install python-dotenv
# .env
API_KEY=MySuperSecretAPIKey
DOMAIN=MyDomain
from dotenv import load_dotenv, dotenv_values
import os
# Set environment variables defined in .env
load_dotenv()
print(os.getenv("API_KEY"))
# Or as a dictionary, without touching environment variables
config = dotenv_values(".env")
print(config["DOMAIN"])
2.1.34. Work with Notion via Python with#
Did you know you can interact with Notion via Python?
notion-client is a Python SDK for working with the Notion API.
You can create databases, search for items, interact with pages, etc.
Check the example below.
!pip install notion-client
from notion_client import Client
notion = Client("<NOTION_TOKEN>")
print(notion.users.list())
my_page = notion.databases.query(
**{
"database_id": "897e5a76-ae52-4b48-9fdf-e71f5945d1af",
"filter": {
"property": "Landmark",
"rich_text": {
"contains": "Bridge",
},
},
}
)
2.1.35. SQL Query Builder in Python#
You can build SQL queries in Python with pypika.
pypika provides a simple interface to build SQL queries with an easy syntax.
It supports nearly every SQL command.
from pypika import Tables, Query
history, customers = Tables('history', 'customers')
q = Query \
.from_(history) \
.join(customers) \
.on(history.customer_id == customers.id) \
.select(history.star) \
.where(customers.id == 5)
q.get_sql()
# SELECT "history".* FROM "history" JOIN "customers"
# ON "history"."customer_id"="customers"."id" WHERE "customers"."id"=5
2.1.36. Text-to-Speech Generation with MeloTTS#
Do you want high-quality text-to-speech in Python?
Use MeloTTS.
MeloTTS supports various languages for speech generation without needing a GPU.
You can use it via CLI, Python API or Web UI.
!git clone https://github.com/myshell-ai/MeloTTS.git
!cd MeloTTS
!pip install -e .
!python -m unidic download
!melo "Text to read" output.wav --language EN
!melo-ui
from melo.api import TTS
speed = 1.0
device = 'cpu'
text = "La lueur dorée du soleil caresse les vagues, peignant le ciel d'une palette éblouissante."
model = TTS(language='FR', device=device)
speaker_ids = model.hps.data.spk2id
output_path = 'fr.wav'
model.tts_to_file(text, speaker_ids['FR'], output_path, speed=speed)
2.1.37. Powerful SQL Parser and Transpiler with SQLGlot#
With SQLGlot, you can parse, optimize, transpile and format SQL queries.
You can even translate between 21 different flavours like DuckDB, Snowflake, Spark and Hive.
!pip install sqlglot
import sqlglot
sqlglot.transpile("SELECT TOP 1 salary FROM employees WHERE age > 30", read="tsql", write="hive")[0]
# SELECT salary FROM employees WHERE age > 30 LIMIT 1
sqlglot.transpile("SELECT foo FROM (SELECT baz FROM t")
#ParseError: Expecting ). Line 1, Col: 34. SELECT foo FROM (SELECT baz FROM t
2.1.38. Prettify Python Errors with pretty_errors#
Are you annoyed from the unclear Python error messages?
Try pretty_errors.
It’s a library to prettify Python exception output to make it more readable and clear.
It also allows you to configure the output like changing colors, separator character, displaying locals, etc..
!pip install pretty_errors
import pretty_errors
# Optional: Configurations
pretty_errors.configure(
separator_character = '*',
filename_display = pretty_errors.FILENAME_EXTENDED,
line_number_first = True,
display_link = True,
lines_before = 5,
lines_after = 2,
line_color = pretty_errors.RED + '> ' + pretty_errors.default_config.line_color,
code_color = ' ' + pretty_errors.default_config.line_color,
truncate_code = True,
display_locals = True
)
x = 10 / 0
2.1.39. Unified Python DataFrame API with ibis#
Are you annoyed by learning a new API for handling dataframes every week?
With ibis, you don’t have to anymore.
ibis defines a Python dataframe API which runs on over 20+ backends.
Polars, Pandas, PySpark, Snowflake, BigQuery - you name it.
You just have to install ibis with the corresponding backend, the rest stays the same.
!pip install 'ibis-framework[duckdb]'
import ibis
# Set different backends
ibis.set_backend("duckdb") # or ibis.set_backend("polars")
conn = ibis.duckdb.connect()
data = conn.read_parquet("data.parquet")
result = data.group_by(["species", "island"]).agg(count=data.count()).order_by("count")
2.1.40. Create Beautiful Tables with great_tables#
Do you want to create nice-looking tables in Python?
Try great_tables.
great_tables lets you create beautiful and high-quality tables with an easy API.
You can use the pre-defined table components like footer, header, and table body by bringing your dataframe.
!pip install great_tables
from great_tables import GT
from great_tables.data import sp500
start_date = "2010-06-07"
end_date = "2010-06-14"
(
GT(sp500)
.tab_header(title="S&P 500", subtitle=f"{start_date} to {end_date}")
.fmt_currency(columns=["open", "high", "low", "close"])
.fmt_date(columns="date", date_style="wd_m_day_year")
.fmt_number(columns="volume", compact=True)
.cols_hide(columns="adj_close")
)
2.1.41. Data Quality Checks for Dataframes with cuallee#
Do you want to make quality checks for your dataframes?
Try cuallee.
cuallee provides an API to validate your dataframe for common things like completeness, dates, anomalies or membership.
cuallee supports the most popular libraries and providers like Polars, DuckDB, BigQuery, and Snowflake.
!pip install cuallee
from cuallee import Check, CheckLevel
check = Check(CheckLevel.WARNING, "Completeness")
(
check
.is_complete("id")
.is_unique("id")
.validate(df)
).show()
check = Check(CheckLevel.WARNING, "CheckIsBetweenDates")
df = spark.sql(
"""
SELECT
explode(
sequence(
to_date('2022-01-01'),
to_date('2022-01-10'),
interval 1 day)) as date
""")
assert (
check.is_between("date", "2022-01-01", "2022-01-10")
.validate(df)
.first()
.status == "PASS"
)
2.1.42. OCR, Line Detection and Layout Analysis with surya#
Do you need an open-source OCR package?
Try surya.
surya is an OCR + layout analysis + line detection library for Python, supporting over 90 languages.
A great alternative to popular libraries like easyocr.
!pip install surya-ocr
from PIL import Image
from surya.ocr import run_ocr
from surya.model.detection import segformer
from surya.model.recognition.model import load_model
from surya.model.recognition.processor import load_processor
image = Image.open(IMAGE_PATH)
langs = ["en"]
det_processor, det_model = segformer.load_processor(), segformer.load_model()
rec_model, rec_processor = load_model(), load_processor()
predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)
2.1.43. Decode/Encode JWTs with PyJWT#
For working with JWT in Python, use PyJWT.
PyJWT is a Python library for encoding/decoding JWTs easily.
!pip install pyjwt
import jwt
encoded_jwt = jwt.encode({"some": "payload"}, "secret", algorithm="HS256")
jwt.decode(encoded_jwt, "secret", algorithms=["HS256"])
2.1.44. Convert HTML to Markdown with markdownify#
To convert HTML to Markdown with Python, use markdownify.
markdownify is a Python library which provides a simple function to convert HTML to markdown.
It also supports many options like stripping out elements.
!pip install markdownify
from markdownify import markdownify as md
md('<b>Yay</b> <a href="http://github.com">GitHub</a>')
# Output: '**Yay** [GitHub](http://github.com)'
2.1.45. Build Web Apps with mesop#
Google Devs published a new open-source Streamlit competitor.
It’s called mesop to build web apps in Python rapidly.
It provides ready-to-use components or you can build your ones, without writing HTML/CSS/JS code.
!pip install mesop
import mesop as me
import mesop.labs as mel
@me.page(path="/chat")
def chat():
mel.chat(transform)
def transform(prompt: str, history: list[mel.ChatMessage]) -> str:
return "Hello " + prompt
2.1.46. Anonymize PII Data with presidio#
Working with PII data can be a neckbreaker in some cases.
Luckily, for fast anonymization, you can use presidio.
presidio handles anonymization of popular entities like names, phone numbers, credit card numbers or Bitcoin wallets.
It can even handle text in images!
!pip install presidio_analyzer presidio_anonymizer
!python -m spacy download en_core_web_lg
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
text_to_anonymize = "His name is Mr. Jones. His phone number is 212-555-5555."
analyzer = AnalyzerEngine()
results = analyzer.analyze(text=text_to_anonymize, entities=["PHONE_NUMBER", "PERSON"], language='en')
anonymizer = AnonymizerEngine()
anonymized_text = anonymizer.anonymize(text=text_to_anonymize, analyzer_results=results)
print(anonymized_text)
# Output: His name is Mr. <PERSON>. His phone number is <PHONE_NUMBER>.
2.1.47. Extract Skills from Job Postings with skillner#
Extracting skills from unstructured data can be difficult.
With 𝐬𝐤𝐢𝐥𝐥𝐧𝐞𝐫 it doesn’t have to be.
𝐬𝐤𝐢𝐥𝐥𝐧𝐞𝐫 extracts skills and certifications from data based on an open source skills database.
Based on spacy and some simple rules, it achieved good results in some tests I ran.
Of course, you could also run an LLM on job ads, but do you need it?
!pip install skillNer
!python -m spacy download en_core_web_lg
import spacy
from spacy.matcher import PhraseMatcher
from skillNer.general_params import SKILL_DB
from skillNer.skill_extractor_class import SkillExtractor
nlp = spacy.load("en_core_web_lg")
skill_extractor = SkillExtractor(nlp, SKILL_DB, PhraseMatcher)
job_description = """
You are a Python developer with a expertise in backend development
and can manage projects. You quickly adapt to new environments
and speak fluently English and German.
"""
annotations = skill_extractor.annotate(job_description)
skill_extractor.describe(annotations)
2.1.48. Rate Limiting FastAPI with slowapi#
Preventing abuse of your API is crucial.
To implement rate limiting for FastAPI, you can use slowapi.
slowapi offers utility functions to limit your FastAPI or Starlette app based on e.g. the IP address.
In the example below, we limit our API to 5 requests per minute.
A note from the author: This is alpha quality code still, the API may change, and things may fall apart while you try it.
!pip install slowapi
from fastapi import FastAPI
from slowapi import Limiter, _rate_limit_exceeded_handler
from slowapi.util import get_remote_address
from slowapi.errors import RateLimitExceeded
# Limiting based on user's IP address
limiter = Limiter(key_func=get_remote_address)
app = FastAPI()
app.state.limiter = limiter
app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
@app.get("/home")
@limiter.limit("5/minute")
async def hello(request: Request):
return {"response":"Hello"}
2.1.49. Create CLI out of any Python Object with fire#
Transform any Python object into a CLI with fire.
fire is a neat library for turning your Python object into a CLI and making the transition between Python and Bash easier.
!pip install fire
# hello.py
import fire
def hello(name="World"):
return "Hello %s!" % name
if __name__ == '__main__':
fire.Fire(hello)
!python hello.py --name=David
2.1.50. Environment Variables Management with pydantic-settings#
Is this the best way to work with environment variables?
pydantic-settings makes it so easy to work with your environment variables in an easy way.
Why it’s a great tool:
Type-safe configuration with zero boilerplate
Automatic environment variable loading
Built-in validation and error handling
Seamless .env file support
For your settings, just create a class which inherits from BaseSettings and define your variables there.
!pip install pydantic-settings
from pydantic_settings import BaseSettings, SettingsConfigDict
from pydanctic import BaseModel
from enum import Enum
class Environment(str, Enum):
DEV = 'dev'
STAGING = 'staging'
PROD = 'prod'
class RedisSettings(BaseModel):
host: str
port: int
class AppSettings(BaseSettings):
model_config = SettingsConfigDict(env_file='.env')
redis: RedisSettings
app_name: str
environment: Environment
debug_mode: bool = False
settings = AppSettings()
print(settings.redis.host)
'''
# .env
APP_NAME=YourAppName
ENVIRONMENT=dev
DEBUG_MODE=False
REDIS='{"host": "localhost", "port": 6379}'
'''
2.1.51. Deduplicate Huge Datasets with semhash#
Deduplicate your data at lightning speed in Python! 🔥
Having duplicates in your dataset is annoying and needs to be removed as they do not contribute positively to model training.
But they can be difficult to detect, especially semantic duplicates.
Fortunately, 𝐬𝐞𝐦𝐡𝐚𝐬𝐡 has you covered!
𝐬𝐞𝐦𝐡𝐚𝐬𝐡 deduplicates your dataset at lightning speed.
It uses fast embedding generation with Model2Vec and optional ANN-based similarity search with Vicinity.
For a dataset of 1.8M rows, 𝐬𝐞𝐦𝐡𝐚𝐬𝐡 takes 83 seconds to deduplicate. 🔥
You can, of course, use any model supported by sentence-transformers, or bring your own model.
!pip install semhash
from datasets import load_dataset
from semhash import SemHash
texts = load_dataset("ag_news", split="train")["text"]
semhash = SemHash.from_records(records=texts)
deduplicated_texts = semhash.self_deduplicate().deduplicated
2.1.52. Fast HTTP Server: robyn#
Do you need a lightweight alternative to FastAPI?
Try out 𝗿𝗼𝗯𝘆𝗻.
𝗿𝗼𝗯𝘆𝗻 is a fast and lightweight web framework written in Rust (like everything else these days).
It combines Python’s async capabilities with a Rust runtime.
With a similar syntax and a great documentation, 𝗿𝗼𝗯𝘆𝗻 makes it easy to switch from other frameworks.
!pip install robyn
# app.py
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def hello_world(request):
return "Hello, world!"
app.start(port=8080)
!python app.py
2.1.53. GZip Compression with FastAPI#
One small trick to optimize your FastAPI application. (with 2 lines of code!)
Whenever your API sends larger amounts of data, GZip compression helps in improving latency and reducing bandwidth usage.
Starlette provides the GZipMiddleware, which can be used by FastAPI to compress the response data.
-> Adjust the minimum_size parameter to set the minimum size before compression is applied. -> Adjust the compresslevel parameter to control how fast the compression is vs how big the compressed file will be.
from fastapi import FastAPI
from starlette.middleware.gzip import GZipMiddleware
app = FastAPI()
app.add_middleware(GZipMiddleware, minimum_size=1000, compresslevel=5)
@app.get("/large-data")
async def get_large_data():
return {"data": [i for i in range(10000)]}
# curl -I -H "Accept-Encoding: gzip" http://127.0.0.1:8000/large-data